




Abstract
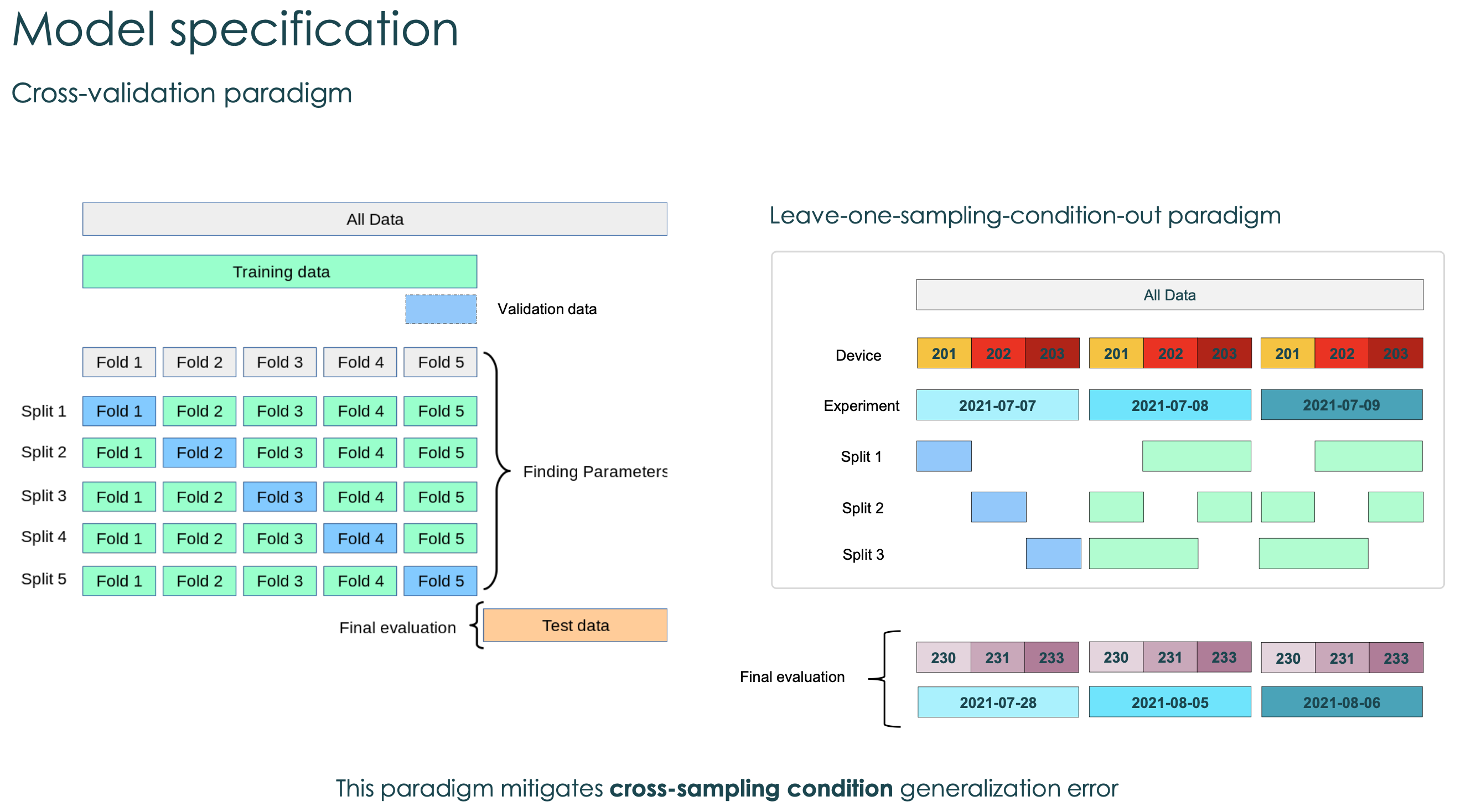
Machine learning models for Artificial Olfaction must overcome three challenges : - Cross-device generalization: the ability of a predictive model trained on a piece of equipment to perform well on data sampled on new pieces of equipment. - Cross-environment generalization: the ability of a predictive model trained in a given environment to perform well on data sampled in a different environment. - Cross-time generalization: the ability of a predictive model to perform well over time despite sensor drift. To assess these sources of errors, we devised a neat cross-validation paradigm allowing to quantify the generalization capacity across each out-of-sample condition. The dataset was generated on a test rig across different sampling conditions (repetition / device / experimental days). Sequential Feature Selection was used to identify the most relevant features for classification of volatile substance. We tested several models and hyperparameters, and found that a linear model with elastic net regularization performed best. We concluded that odor classification accuracy was stable across devices and over a reasonable time span (i.e., at least three months). Our results also showed that environmental variations (i.e., background noise) was the dominating component of generalization error, but that it could be in part compensated for by proper normalization of sensor signal. These results were used to improve sensor preprocessing routines of the company's odor recognition module.