
On April 17th, I attended the discussion hosting Yann LeCun, head of AI research at Facebook, and Frédérique de Vignemont, a french Philosopher director of the Jean Nicod institute, at the NYU campus in Paris. I had never been aware that a NYU campus was established at the epicenter of Paris academic life since 2014, hidden behind a low-key gateway squeezed between two entrances of the Eyrolles bookstore of the Boulevard Saint-Germain.
An engineer’s take on a big scientific quest
Section titled [object Undefined]The last public conference I had seen from Yann LeCun, back in 20181, had left me in awe: starting from a very didactic presentation of the fundamentals of statistical learning (essentially, the art of interpolating data points), LeCun had revisited the fundamental bias/variance dilemma in machine learning, to reach the staggering conclusion that models with infinite degrees of freedom can not learn anything (unless we have infinite data), hence knowledge is inherently limited.
This conference was pure philosophy of knowledge, stripped down of epistemological jargon.
Thus my expectations were high as I was waiting to hear the thoughts of the inventor of Deep Learning2 on what the latest achievements of “generative AI”, largely inflated by media uproar, meant for the future of AI.
A lively discussion that gave plenty food for thoughts
Section titled [object Undefined]As I have since long lost track of the academic agenda of Philosophy of the Mind, I don’t know the work of Mrs de Vignemont. To the neuroscientist I once was, this area of philosophy is largely testimonial anyway: all the scientific questions over which philosophers once held sway, ought to be, and can increasingly be, scientifically addressed using a combination of functional neuroimaging, experimental cognitive psychology, and statistical modelling.
This “scientization” of brain science has relegated ill-posed questions (👋 qualia) to a cabinet of epistemological curiosities. Instead, we can concentrate on the critical questions that, even if they are sometimes a stretch for empirical testing, are at least within reach of AI-driven research and engineering insights:
-
With regards to Large Language Models (LLMs) achievements, what does language competence really means? Will we be able to prevent LLMs from hallucinating solely by empowering them with planning abilities, or is grounding3 needed? What would the neural net architectural substrates of grounding be?
-
What does the success of LLMs model imply for the supposedly uniqueness of our brain’s architecture, shaped by millions of years of natural selection, in the emergence of advanced cognitive abilities? The success of CNN and Transformer architectures in very difficult tasks suggests that human-designed cognitive systems can emulate some of the most advanced cognitive functions performed by our brains. True, baby brains are far more impressive in their inference capabilities and data frugality, but isn’t it just a matter of getting the architecture and the training paradigm right?
One must recognize that the cognitive science background of Mrs de Vignemont was on point to steer the discussions on these topics. She came up with truly relevant inputs to the conversation, which would have provided solid grounds for a more in depth discussion of what reproducing the brain in silico really entails.
The dialog between the two speakers and their audience brought up several interesting philosophical and engineering questions, some of which I recall below:
Can LLMs hallucinations be treated?
Section titled [object Undefined]Not within their current training paradigm which consists of chained prediction of the next most probable word. This design makes prediction necessarily diverge from the correct path as prediction errors accumulate along the way. The hallucination phenomenon can somewhat be allievated using curated data and adjust human feedback (be prepared to see more and more LLMs releases in the coming months), but training LLMs to plan sentences ahead instead of just the next token (“to think before they speak”, to say it anthropomorphically) requires a rethinking of their architecture and optimization functions altogether.
Language is not the epitome of intelligence
Section titled [object Undefined]Language is taken to be the epitome of intelligence, but it turned out to be far less difficult to “solve” (more on that below) than supposedly more “basic” tasks like driving a car (which a teenager can learn in less than 20 hours) or having goal-oriented behaviour in the real world (like filling a dishwasher, a task three year olds can do just fine).
Chomsky was wrong
Section titled [object Undefined]“Language can be learned from scratch, without any evolutionarily imposed innate structure”.
Behind its apparent simplicity, this is a highly controversial claim. Although I do agree with LeCun that there is no a priori reason to contend that brain features can not be recapitulated by deep neural net architecture independent of natural selection design, the claim that language has been or even could be acquired by computers is a cheeky one.
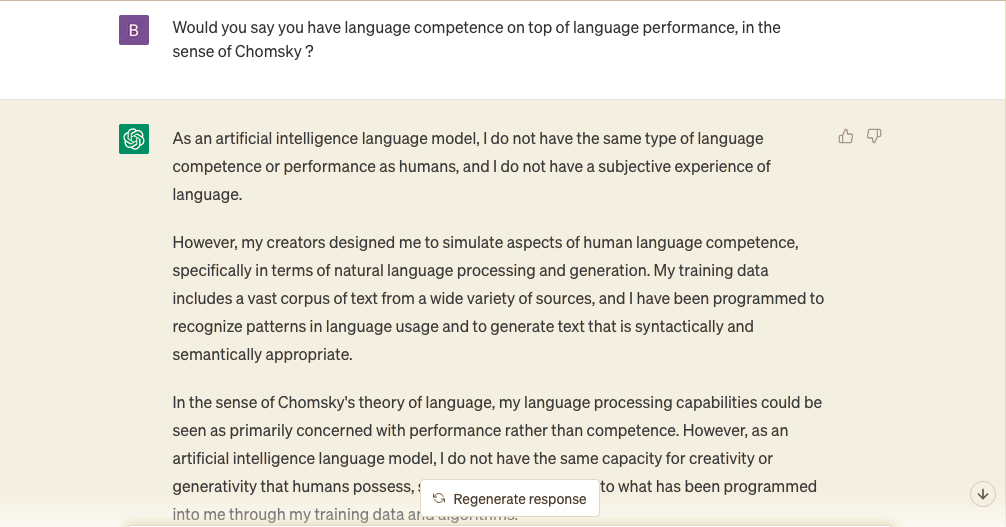
But it is certain that classic stands about languages do not hold anymore in the face of the latest achievements of LLMs. For example, experimenting with ChatGPT raises question about the relevance of the chomskyan difference between language competence (the speaker’s knowledge of her language) and language performance (the speaker’s ability to use her language in concrete situation). When asked if an absurd sentence is correct, the bot is able to explain why it is not:

This answer gives the impression that the model has some kind of comprehension of what is signified by language. We know, however, that under the hood, it relies on the same autoregressive utterance of words, such that one could almost say that the LLM exhibits language performance of language competence. This “meta-language performance” is quite elaborate:

This interaction highlights the limits of the distinction Chomsky reasserted in a recent piece in the NYT4, between the ability to use language to describe the world, and the ability to use language to explain the world. What criteria can be used to distinguish the “phenomenological” account of language made by the OpenAI chatbot, from the one humans make? Have autoregressive LLMs managed to entirely dissolve the endlessy autoregressive, non-sensical questions of phenomenology? I believe they have, quite ironically:
Can neural networks be emboddied?
Section titled [object Undefined]How can we emboddy AI from an engineering perspective, such that a machine could acquire common sense, for example of the physical world like babies do?
This question points towards a big field of research using “foundation models”5.
Biomicking versus Bio inspiration
Section titled [object Undefined]Is it more advisable to copy the brain or just get inspiration from it to design better artificial systems?
The relative failure of the blue brain project6, and the success of artificial neural networks as modelling tools for systems neuroscience argue in favour of the second option. Convolutional neural networks are commonly used in visual neuroscience to model cortical responses in V17, although the brain does not implement convolution.
Conversely, comparisons of the representations elicited in biological cortices and artificial layers of deep learning networks can provide powerful inspiration to orientate research in artificial intelligence. In an elegant and fascinating paper8 by FAIR’s team in Paris, researchers found that the correlation between the cortical representations of speech and the activity in layers of a GPT-2 network increases when the neural network activation states are concatenated accross multiple timesteps. That is, a LLM representing the unfold of speech over time better reflects how the brain processes speech.
Overall, it was a very intellectually refreshing evening listening to LeCun think as an engineer about big scientific questions.
Epilogue: the unreasonnable success of some AI products
Section titled [object Undefined]During the cocktail, I asked LeCun why Meta had marketed Galactica as a scientific assistant, when they were perfectly aware of the hallucination issues plaguing LLMs. How could they have overlooked that an AI assistant for scientific writing needed to be grounded in truth? This fiasco was a big setback for the company, especially considering the later success of the equally flawed OpenAI ChatGPT. LeCun blamed scientists’ mischief with Galactica demo, and the prejudice people hold against Meta (the latter was arguably a factor in the outcry).
I think this episode highlights an important pitfall when making end-consumer “AI products”, and advertising them as such. Some of the most essential digital tools we use in our daily life ship with very fancy deep learning algorithms, but all the magic happens under the hood, which make their limitations non deceptive.
In contrast, deceived customer expectations due to mislabeling of an AI product cannot be recovered from. OpenAI was clever in positioning ChatGPT as a cool chatbot that can engage in conversations about everything, because that is essentialy one are where the model excels, despite all its shortcomings. Had it been marketed as a developper assistant, though, it would have been torn apart because of its frequent coding mistakes.
Nevertheless, ChatGPT-like models have quietly become an indispensable asset for developers - a behind-the-scenes workhorse doing the heavy lifting. And as we have grown accustomed to it, ChatGPT is transforming into an essential tool in our daily digital toolkit.
References
Section titled [object Undefined]Footnotes
Section titled [object Undefined]-
La théorie de l’apprentissage de Vapnik et les progrès récents de l’IA ↩
-
How 3 Turing Awardees Republished Key Methods and Ideas Whose Creators They Failed to Credit, Jürgen Schmidhuber’s blog ↩
-
Convolutional Neural Networks as a Model of the Visual System: Past, Present, and Future ↩
-
Evidence of a predictive coding hierarchy in the human brain listening to speech ↩