As machine learning engineers, we take a lot of things for granted to focus on delivering business-relevant solutions.
Recently, I found myself teaching some deep learning classes, and noticed a gap in my knowledge when transitioning from the historical / textbook presentation of fully-connected feed-forward networks (i.e., the so-called multi-layer perceptrons) to the specific loss and activation functions used in neural network classifiers.
In this article, I explain the rational behind the peculiarities of classifier neural networks:
- the Sigmoid activation function
- the Cross-Entropy loss and its variations
- the daunting Softmax activation function
I always start from intuitions and complement each insight with some down-to-earth calculus walkthrough. Although linear algebra competencies are, I believe, not required to apprehend Machine or Deep learning, and even less so for leveraging it in real-world applications, digging into the maths is actually necessary to really comprehend any machine learning notion.
This piece is intended for scientifically literate readers who wants to deepen their understanding of neural networks for classification; senior machine learning engineers or PhDs will find all this trivial.
Deep learning explained from multiple perspectives
Section titled [object Undefined]An aspiring machine learning engineer who just finished a bootcamp on deep neural networks may have built herself a multi-level knowledge map to structure her insights from multiple perspectives.
Layman’s perspective
Section titled [object Undefined]Deep learning is a subdomain of machine learning which employs neural networks to solve complex prediction tasks. This “complexity” stems from the shere dimensionality of the data (cf. Curse of dimensionality1), or the sophistication of pattern recognitions tasks2 which makes traditional, “shallow” machine learning methods suboptimal or plain impractical.
Statistical learning perspective
Section titled [object Undefined]Deep neural network architectures stack multiple data processing nodes organized in layers. Each node performs a weighted sum of inputs followed by a transformation through an activation function. The succession of layers and activation functions allows for the extraction of multiple abstract and hierarchical representations of the original data (a process termed Representation Learning).
These representations are learned by the networks insofar they are relevant for solving the task.
Computational perspective
Section titled [object Undefined]Learning effective representations of the data essentially involves fine-tuning the weight settings of the connections between nodes, so as to minimize the gap between the predicted outputs at the terminal nodes and the target values the network aims to predict.
Each training pass of a deep neural network consists in a forward and a backward pass over training samples.
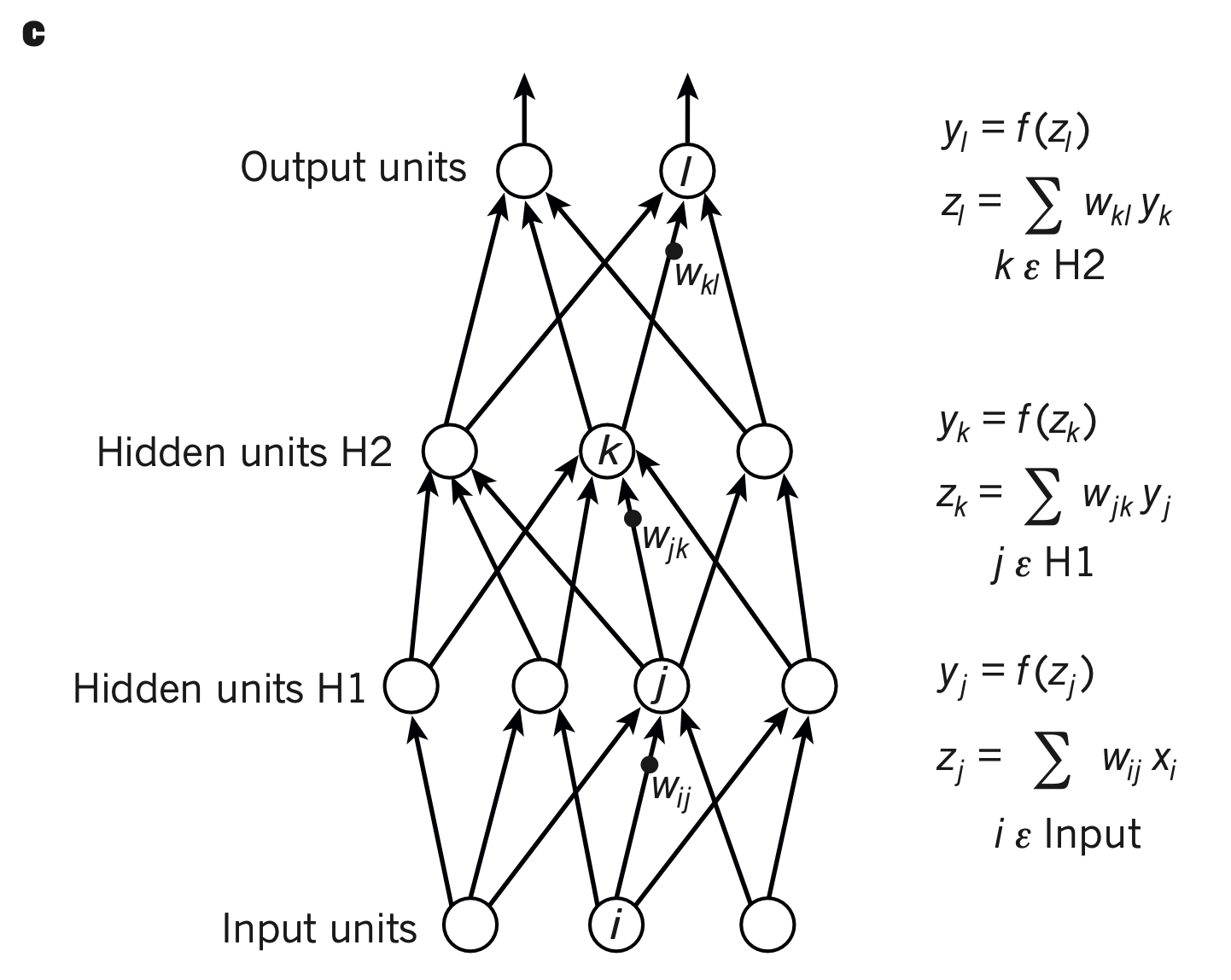
In practice, training samples are supplied as “batches”, however, for illustrative purposes, let us consider the processing of a single training data point, following Figure 1 of LeCun et al., 20152.
-
During the forward pass, we compute the activity of each node of each layer as a weighted sum of its inputs, transformed by an activity function.
For example, to get the ouput of a node at hidden layer , we first compute a weighted sum of its three inputs:
and pass the result in an activation function to get the activity of the node (usually written as , here written in Figure c):
The activity at all nodes of a layer forms an activity vector which is used as an input layer for nodes of subsequent layers: nodes of layer compute weighted sums of the activity vector of layer H1. Nodes of the output layer compute weighted sums of the activity vector to output a bidimensional vector of values (the Output units below):
Our goal when training a neural network is to optimize the weights so that the output of the network corresponds to the target.
-
During the backward pass, we adjust the weights of the connections between nodes in the direction that minimizes the prediction error.
To do this:
-
We evaluate an objective function (also called a cost function or a loss function) which quantifies the error of the actual output of the network relative to the expected output.
For a regression task (i.e., predicting a continuous value), the square of the residual is used:
where: is the target value and is the prediction of the node (sometimes refered to as score of the node)
-
for each node, we compute a formula that gives us the amount of variation in the cost function for a small change in the parameters of the node. That is, we compute the partial derivatives of the cost function relative to each of the parameters of the node.
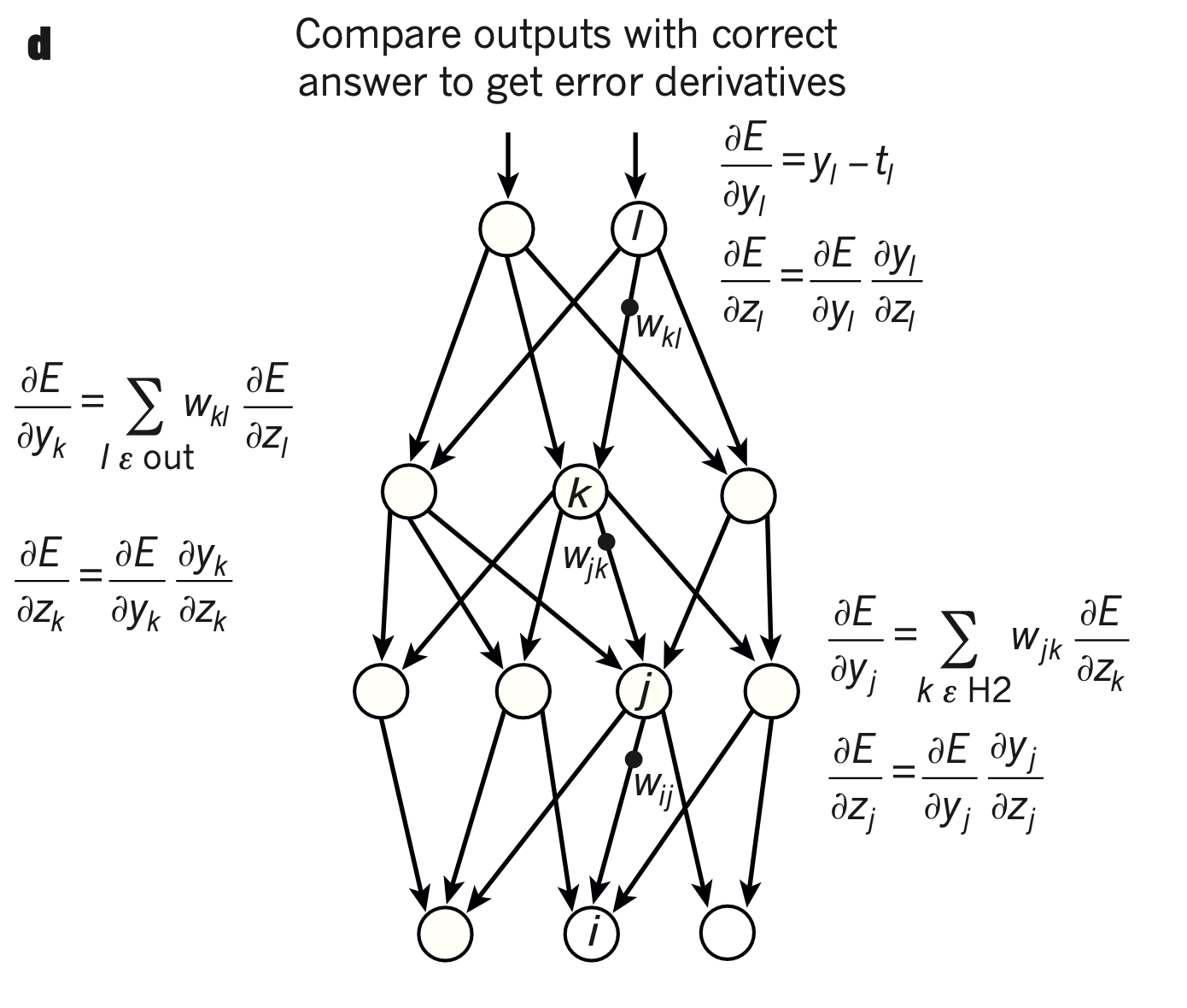
This procedure is dauntingly termed “backpropagation of the gradient of error” because we start from the most distal node, and use the chain rule of derivatives to compute the partial derivatives of the cost function relative to every parameters further up the network.
What is a gradient ?
A gradient is just a vector of partial derivatives of a function with respect to each of its parameters.Thus the gradient of the function summing the n=3 inputs , and from layer at node can be written:
Even though a gradient is technically a vector, the expression “the gradient of x” is used interchangeably with the the technically correct expression “the partial derivative of x with respect to y”, for brevity.
The following sections are verbose explicitation of Figure 1’s legend of LeCun et al., 2015 Nature review2, and worth reading if you are not familiar with neural networks and gradient descent algorithm.
Walkthrough on the computation steps required to update weights
Our goal is to update the network’s weights by minimizing the error. To achieve this, we aim to compute the partial derivative of the loss function with respect to each weight. We will then use these derivatives to update the weights in a direction that minimizes the error (i.e., in the oppositive direction of the derivatives).
Here is an example for updating the weight connecting a hidden node to an output node .
At each training pass, we update the weight as follows:
with the learning rate.
How do we derive ? We will “just” use derivatives rules to compute, step by step, the derivative of the composition of functions that maps to the cost function .
For a neater derivation expression, we scale the cost function by . We also substitute for (the target value), and , the output of our final node, by , the notation used in Figure d:
We express the derivative of the cost function expression with respect to :
Then, applying the chain rule gives us:
Simplifying and injecting the equation gives us:
Applying the sum rule, we can write:
The derivative of a constant being 0, this simplifies as:
Applying the chain rule again:
If the ouput layer is a multiregression layer, i.e., is the identify function, then and the expression simplifies to:
Injecting the expression of in the equation:
When deriving the weighted sum with respect to one of the weight, all the other weights are treated as constants and hence the final expression:
The weight will be updated in proportion of the input and the magnitude of deviation from the target .
The backpropagation algorithm
As stated by LeCun et al., “the backpropagation procedure to compute the gradient of an objective function with respect to the weights of a multilayer stack of modules is nothing more than a practical application of the chain rule for derivatives.”.
During backpropagation, we start by computing the error derivative relative to the end node inputs, and store the intermediate calculations to continue propagating the error derivatives further up the network.
For an enlightning walkthrough into the matrix implementation of backpropagation, I recommend reading this excellent blog post3 of Brent Scarff. For a visually compelling illustration of backpropagation, follow this video4. For a deep dive into the linear algebra intricacies, follow along Chapter 25 of Neural Network and Deep Learning by Michael Nielson. Sebastian Raschka also has a very good didactic post6 on backpropagation in artificial neural networks.
For the purpose of the current article, I will just extend my casual, down to earth example initiated above to illustrate the logic of backpropagation.
If we now want to update the weights of the last hidden layer, i.e., compute , we must evaluate the following expression:
The sole additional complication for a connected hidden node (a “deep” node) is that the derivative of the loss function with respect to the ouput of the node depends on the error derivative of all the downstream nodes it connects to.
For a node , that is:
As , we obtain:
Reinjecting it in the above expression gives us:
As shown in the walkthrough above, and this expression becomes:
The evaluation of this expression depends on the loss and activation functions used at nodes and .
Compared to the single walkthrough outlined above, the backpropagation of gradient of error algorithm consists in computing the gradients of error at each layer (e.g., for hidden layer , we compute )
These gradients are computed once during the backward pass, stored, and reused for all upstream calculations.
As we showed, computing the derivatives with respect to the weights of the final layer is straightforward:
For the last hidden layer, it is a bit more involved, and depends on the error derivative at the nodes downstream:
We can express it as a function of the derivative of the loss function with respect to the weighted sum of inputs of the node:
In plain english, as we progress upwards, we multiply the derivative of the loss function with respect to the output of the node, by the derivative of the activation function of the node. This yields the derivative of the loss function with respect to the weighted sum of inputs at the node.
This term is used:
- to compute the derivative of the loss function with respect to the weights connecting the node with nodes of the previous layer, e.g., .
- to continue propagating the error gradient further up the network.
-
Machine learning practionner perspective
Section titled [object Undefined]Given a demanding machine learning problem, we devise a deep learning architecture to map an input layer of data features to an output layer comprising one or more output nodes.
The architectural choices of the inner layers is pretty much free ; yet choosing the proper final layer, activation function and loss function depend on the predictive task of the network:
- For a regression task (i.e., predicting one or several continuous values), we use the Mean Absolute Error (MAE) or Mean Squared Error (MSE) loss. Fundamentally, this is “just” optimization by means of gradient descent instead of ordinary least square.
- For a binary classification task (i.e., distinguishing between two classes), we use a single output node with the Sigmoid activation function, and the Binary Cross-Entropy criterion as a loss function.
- for a multi-class classification task (i.e., distinguishing between several classes), we use multiple nodes with the Softmax activation function and the Cross-Entropy criterion as the loss function.
The Pytorch API has dedicated classes which exposes these last two combinations of activation / loss functions as unified logical blocks: nn.BCEWithLogitsLoss and nn.CrossEntropyLoss.
The raison d’être of sigmoid, cross-entropy, and softmax functions
Section titled [object Undefined]Why do we need to use different activation / loss function combinations in classification tasks?
Well, it turns out we need not to:
- If you train a neural network on a binary classification task using MSE or MAE loss, your network will still manage to learn something, albeit more slowly.
- If you train a neural network on a multi-class classification problem with a sigmoid activation function, your network will learn just fine. But you may ask why use the softmax activation function at all, then ?
We shall see, however, that using the correct combination of activation / loss functions in classification tasks:
- increases training performance
- improves interpretability of the network’s output
As it is often the case with statistics or machine learning topics, we can build an intuition of these phenomenons, but fully grasping it will require us to dig into the derivatives to actually verify our gut feelings.
Computations at classifiers nodes
Section titled [object Undefined]In classification tasks, we seek to assign one (multi-class classification) or several (multi-label classification) labels to a data point given its feature array.
We will first consider the most simple multi-class classification task.
Binary classification task: the rational for the sigmoid function
Section titled [object Undefined]For a binary classification task, our network is tasked to predict a discrete label (yes / no) from a feature vector.
Transforming our two discrete categories into a numerical array that can be used in gradient descent is quite straightforward: we can just assign a positive value (1) to the positive label, and 0 otherwise.
Let us imagine that we train one of the final node from above to predict 0 or 1. In order to calculate our loss, we need to map the result of the computation accomplished by the node (that is, a weighted sum of its inputs) between 0 or 1.
The most obvious solution is to use a step function, for example cutting the domain in half to output 1 if the weighted sum is positive, and 0 otherwise:
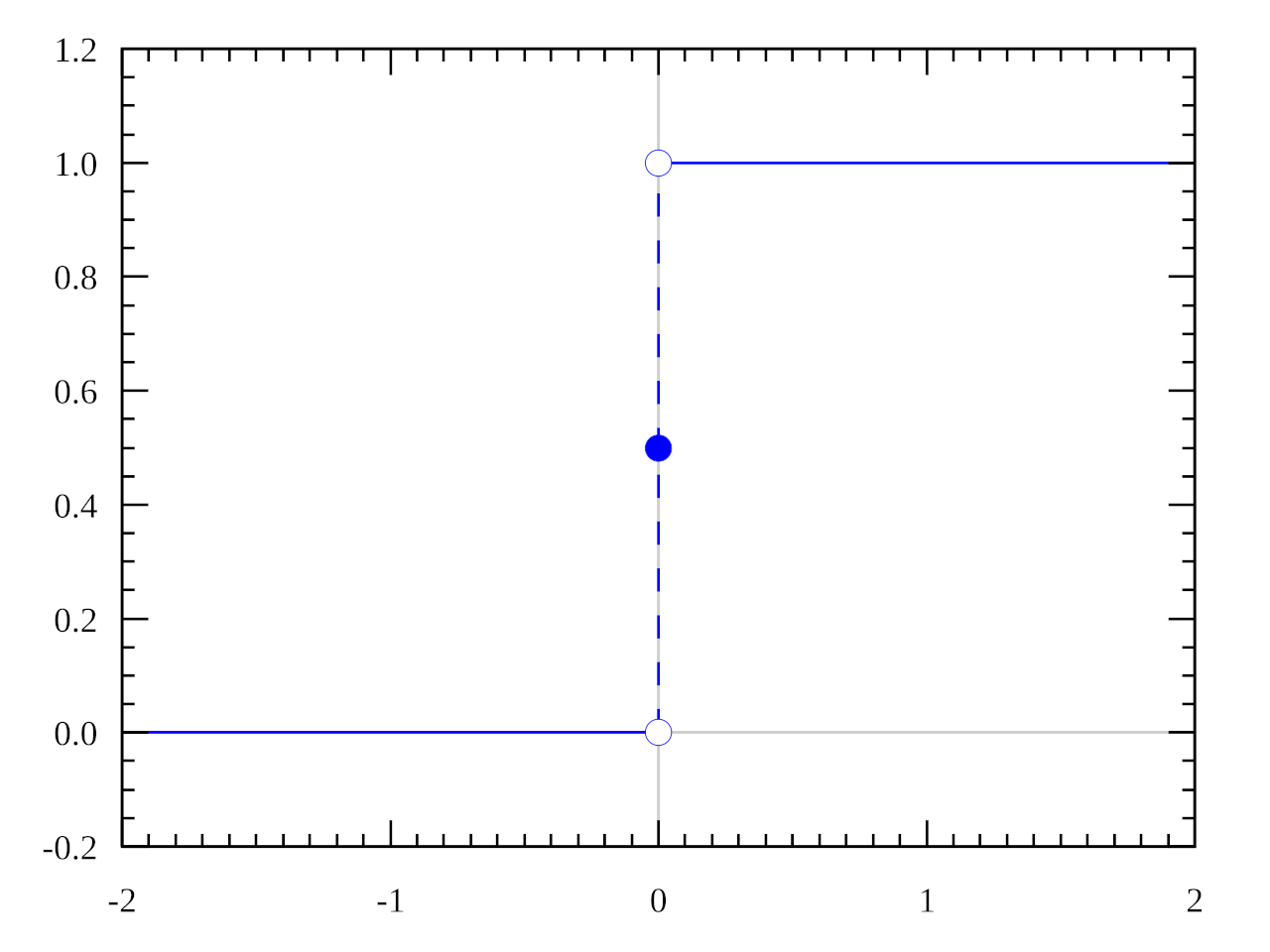
This activation function, called a step function, is used by the perceptron, the most ancient single layer single neuron “network” for supervised learning.
Leveraging the output of this function to measure the performance of our network is straightforward: the loss should be equal to 0 when ground truth and predicted label coincide, and positive otherwise. Thus, the residual square loss, which quantifies the discrepancy between predictions and ground truths in regression tasks can also be used in our classification task:
However, there is a big problem with using a step function as an activation function in a neural network: it has a gradient of 0 everywhere (except at x=0, where the function is not defined and its derivative is infinite).
This means that the rate of change in the output of the step function is constant with respect to the changes in the node parameters in the two subdomains where it is defined ( and ). Thus, the error derivative of the output node with respect to (the weighted sum of inputs at the node) will always be 0, and backpropagation will never update any weights in our network !!
The only error signal that can be extracted from a step function is the label discrepancy itself: this is the error measurement used by the perceptron rule7.
Instead, we want to use a differentiable activation function, whose variation in output reflects small changes in the weighted sum of inputs.
This is precisely the behaviour of the sigmoid activation function:
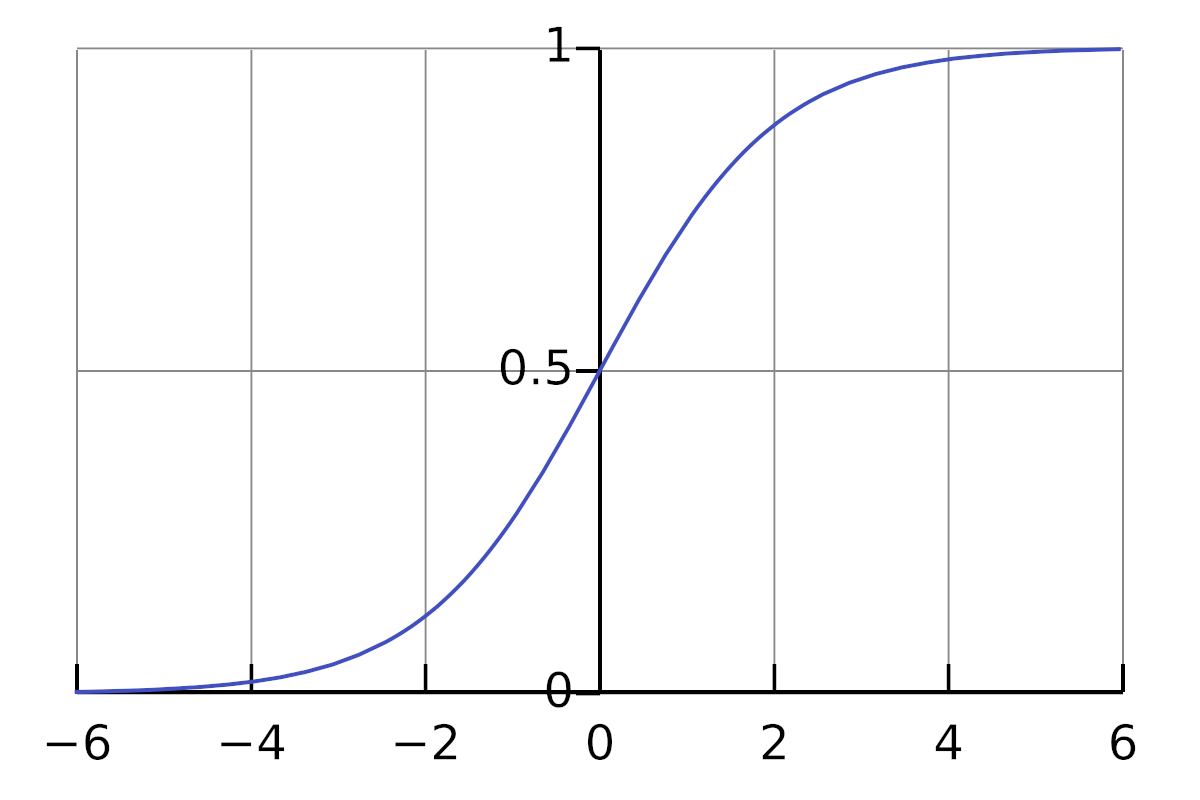
We can see that when , and when ,
The sigmoid function is differentiable8:
So we can compute the derivative of the loss function with respect to the network’s weights.
Walkthrough of the derivation of the residual square error function with respect to output node parameters
We start again from this equation:
If the ouput node is now a sigmoid-activated node, i.e., is the sigmoid function, we have:
This means the weight will be updated in proportion of the input , the magnitude of deviation from the target , and the derivative of the sigmoid function with respect to , .
The problem of learning saturation
Section titled [object Undefined]There is yet a difficulty when using this function with backpropagation: it saturates.
For an output close to 0 or 1, the sigmoid curve flattens, which means mathematically that the gradient (the blue curve on the figure below) gets small:

As the derivative of the loss function with respect to can be expressed as:
We can distinguish between two cases during a training pass:
- The discrepancy between predicted label and ground truth is small (i.e., the network predict near 0 for a negative sample and near 1 for a positive sample): , and . There is little update of the weights, this is the appropriate behaviour.
- The discrepancy between predicted label and ground truth is very big (i.e., the network predict 0 for a positive sample and 1 for a negative sample). Although the absolute value of the first term of the equation tends to 1 (), , because we are in the “floor” (if ) or “ceiling” (if ) zone of the sigmoid function.
So the further our prediction from the ground truth, the smaller the derivative of the loss function with respect to the weights, and thereby the smaller the weight update by gradient descent !!
This is exactly the opposite of our goal: ideally, we would like a big margin of error to lead to a big correction of the weight.
The cross-entropy criterion
Section titled [object Undefined]To remedy this problem of learning saturation, we need a cost function that penalizes the network in proportion of the deviation of the prediction from ground truth.
A way to approach this is to quantify the similarity between the distribution of predicted probabilities of the label by the final node, and the distribution of the “true” probability of the label (that is, 0 or 1).
And there enters the Cross-Entropy (CE) criterion:
This formula calculates the cross-entropy between two probability distributions and :
- is the true probability of an event , which we want to predict.
- is the logarithm of the predicted probability of the same event by our model.
- The sum of this product is taken over all events.
Although this has a profound meaning in information theory9, it is rather abstruse as such.
Yet it is surprisingly effective for defining cost functions in classification tasks, as we shall see in the next sections.
The binary cross-entropy function
Section titled [object Undefined]The Binary Cross-Entropy (BCE) function is an application of the cross-entropy criterion for the definition of the loss of a binary classifier:
This loss computes the sum of the cross-entropy criterion between the distribution of true and predicted probabilities of a positive () and negative () label, averaged across training samples.
Although this expression may be difficult to grasp at first sight, plugging in some toy examples of maximal label and ground truth discrepancies is easy:
- when and , then
- when and , then
Conversely, when and agree,
Intuitively, this cost function solves the problem poised by the saturation of the sigmoid function. We can verify this by working out the derivatives of the binary cross-entropy with respect to the weights of the network:
Walkthrough of the derivation of the cross-entropy loss function with respect to output node parameters
By substituting the residual square loss function with the cross-entropy loss in the expression of the error derivative with respect to the weight , plugging in and we obtain:
Taking the derivative of the logarithm and applying the difference rule of derivative bring us to:
Working a common denominator and simplifying:
Injecting the derivative of the sigmoid function with respect to the sum of inputs gives us:
Which simplifies to:
In plain english, this means that the derivative is proportional to : the greater the discrepancy between prediction and ground truth, the stronger we update the weight. This makes perfect sense.
Moreover, the cross-entropy loss function eliminates the dependency of the gradient of error on the sigmoid derivative, thus avoiding learning saturation.
Generalizing cross-entropy for multi-node classification
Section titled [object Undefined]The binary cross-entropy cost function can easily be generalized to a multi-class or multi-label paradigm using an output layer with more than one node.
-
In multi-class classification, we seek to predict one exclusive label out of classes. The target vector is a one-hot vector of size with a 1 (encoding the positive class) and 0s (encoding the negative classes).
-
In multi-label classification, we seek to predict -possibly- more than one labels from a set of non-exclusive classes. The target vector is a vector of size of 0s and 1s.
For such tasks, we design the final output layer with as many nodes as they are classes: each node encodes the probability of the data point belonging to the corresponding class .
The proper cost function will differ however, given the task.
Multi-label classification
Section titled [object Undefined]In multi-label classification, predictions are independent, so we just have to sum the binary cross-entropy costs across all nodes to calculate our total error:
And use this error to optimize the weights.
Derivation of the multi-label cross-entropy loss function with respect to output node parameters
When deriving with respect to a node output , all the other outputs are treated as constants and we fall back on the expression of the error derivative for a single output node network:
Given a data point, the score of each node of the output layer will encode the probability estimate of the corresponding label.
Multi-class classification
Section titled [object Undefined]In multi-class classification, we train the network to assign each data point to the unique class it belongs to.
Optimizing the binary cross-entropy cost function across several nodes as in the multi-label paradigm will work just fine, but is suboptimal when it comes to interpreting our network’s output.
Indeed, the vector of probabilities concatenated from the output nodes can not be interpreted as the network’s estimate of correct class probability:
- The predictions do not sum to 1.
- The relative score of the output nodes can not be jointly interpreted: the output of each nodes are independently trained in as many binary classification tasks as they are of possible target classes.
So we need to:
- Extend the cross-entropy cost function to handle multiple (C > 2) classes.
- Constrain the prediction layer into representing a vector of probabilities over mutually exclusive targets.
Multi-class cross-entropy
Section titled [object Undefined]Extending cross-entropy to handle classes is straightforward:
Where and are the ground truths and the predictions of the output node for each class in .
As only one class is possible for each sample, the formula simplifies to , where is the log of the probability of the correct class.
However, we can not directly apply this formula to the output layer of sigmoid-activated nodes:
Derivation of the multi-class cross-entropy loss function with respect to output node parameters
We note the target’s label of node :
-
if :
-
if , and , nothing happens at the node.
Thus, using this cross-entropy formulation with one-hot vector targets will only update the weights of the node predicting the probability of the target class. This means that:
- There is no warranty for the target’s output node to have the higher score, i.e., the network does not control for false positive predictions by off-target nodes, making the system unreliable.
- The vector of scores given a feature array is even more problematic to interpret.
The Softmax trick
Section titled [object Undefined]To constrain the prediction layer into representing a vector of probability across mutually exclusive targets, a final piece of computational refinement is used, the softmax activation function:
In plain english, this boils down to normalizing the activity of each output node by the sum of the activity over the entire output layer.
The most appealing property of this transformation is that it converts the raw scores (or “logits”) at the output of the final nodes into a probability distribution (i.e., a vector that sums to 1). This is handy because it allows us to interpret predictions of the final nodes as the network’s estimate of the probability that the correct output is .
💡 You will often read the term “logits” for the outputs of a classification model. It refers to the vector of raw, untransformed outputs of the final layer () before they are passed into a normalization function (sigmoid or softmax).
- In a binary classification problem, the logit is the () input of the single final node which is passed to the sigmoid activation function.
- In a multi-class classification problem, logits are the () inputs to the softmax function.
Why is it called softmax?
Section titled [object Undefined]The softmax activation function should actually be called softargmax. Softmax can indeed be considered a “soft” version of the argmax function: Instead of returning a 1 at the position of the maximum element in the vector, and 0 for the rest, it returns the highest value at the position of the maximum element, and small values for the rest of the vector.
The use of the exponential function ensures that:
- Every output value is positive.
- The largest components in the input vector remains the largest in the output vector.
- The normalization function is differentiable, enabling the seamless application of the chain rule for the computation of the error derivative during backpropagation.
The Categorical Cross-Entropy loss
Section titled [object Undefined]Injecting the formula for softmax normalization in the cross-entropy loss function, we can write:
The combination of the softmax activation function with the cross-entropy loss is refered to as the Categorical Cross-entropy loss. Computing its derivative is a bit more involved than what we did up to now, because it depends:
- On the output node we want to find the derivative for (in an analogous way to the walkthrough above, where we considered the derivative of the loss function at the node predicting the probability of the positive class, versus all the other nodes where it equals 0).
- With respect to which input of the softmax function we want to compute the derivative of the loss function of the node.
There are lots of bits and pieces over the internet exposing the derivation of the softmax and cross-entropy loss functions ; but they are often hard to follow because they all use different notation conventions, derivation steps, and math junkies tricks. The most rigorous and comprehensive exploration of the matter I could find is on Eli Bendersky’s site10
In the section below, I walk through a down to earth derivation of the categorical cross-entropy loss function applied to our dual output node network.
In the end, we show that the derivative of the loss function with respect to the weights of the network is identical to applying the binary cross entropy across sigmoid-activated nodes.
Walkthrough of the derivation of the categorical cross-entropy loss function with respect to output node parameters
As previously, we are interested in computing the derivative of the loss function with respect to the weight .
Using the chain rule to express the derivative of the cost function with respect to the weight , we can write:
The important point to note when using the softmax activation function is that the gradient of the output of any node , depends on the weighted sum of inputs of all other output nodes. So we need to use different node subscripts to distinguish between before and after softmax activation nodes. We introduce , which identify the index of the class.
The derivative of the cross-entropy loss with respect to the sum of inputs of the node is:
Applying the chain rule, we obtain:
We want to compute the derivative of the softmax output at node with respect to the sum of inputs at node . For clarity, I will condense the denominator of the softmax into .
We need to distinguish between two cases:
-
if :
Using the quotient rule, we get:
[Hints: and ]
-
if :
During derivation, is treated as a constant and applying the quotient rule gets us to:
We can now compute the derivative of the cross-entropy loss with respect to . First we take the derivative of the log:
We can now inject our two equations of the derivative of the softmax output with respect to inputs into the expression.
Note that for the condition, we use the subscript:
This expression simplifies to:
If we reintegrate in the sum over all nodes , we get:
Given that the one-hot vector sums to one, and we arrive to the final expression:
Closing the loop, if we express as :
Which is equivalent to the expression we derived from multi-node binary cross-entropy loss.
Thus, using the categorical cross-entropy loss:
- transforms the network’s output into an estimate of the correct class probability among multiple mutually exclusive classes.
- avoids learning saturation.
Conclusions
Section titled [object Undefined]And there ends our journey through the activation and loss functions used in neural network classifiers.
We covered:
- The principles of feed-forward and backward passes in neural networks.
- How the backpropagation algorithm is used to optimize the weights of a neural network.
- The rational behind the sigmoid activation function used in classification tasks.
- Why the cross-entropy loss function avoids learning saturation caused by the sigmoid function.
- How the combination of softmax activation and cross-entropy loss functions allow for optimal learning and interpretability of the predictions of neural network classifiers.
References
Section titled [object Undefined]Footnotes
Section titled [object Undefined]-
How the backpropagation algorithm works, in Neural Networks and Deep Learning by Michael Neuser ↩
-
How to compute gradients with backpropagation for arbitrary loss and activation functions?, by Sebastian Raschka ↩
-
What is the difference between a Perceptron, Adaline, and neural network model?, by Sebastian Raschka ↩